Extending Neovim for blogging
Browse posts with telescope.nvim ★
I’ve used telescope.nvim's find files with
require("telescope.builtin").find_files for quite some time.
I use find files together with it’s cousin .oldfiles (find recently opened files) all the time for finding source code files, blog posts, and more.
But it’s naturally restricted to operate on only filenames and you can make telescope richer by operating on structured data.
So let’s move away from using the files finder to find posts:
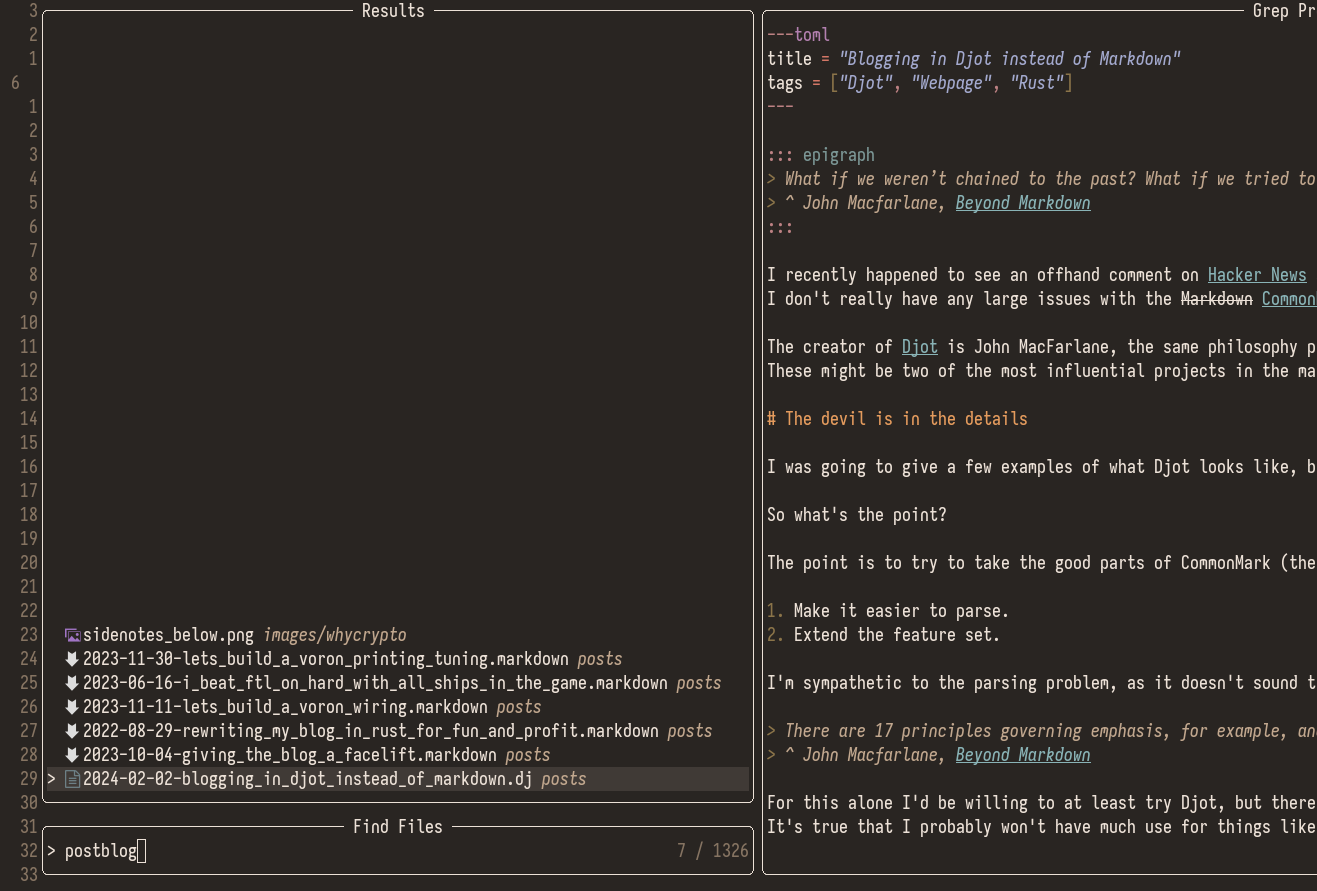
To a custom posts picker that display posts in a neater way and allows us to filter using tags or other metadata:
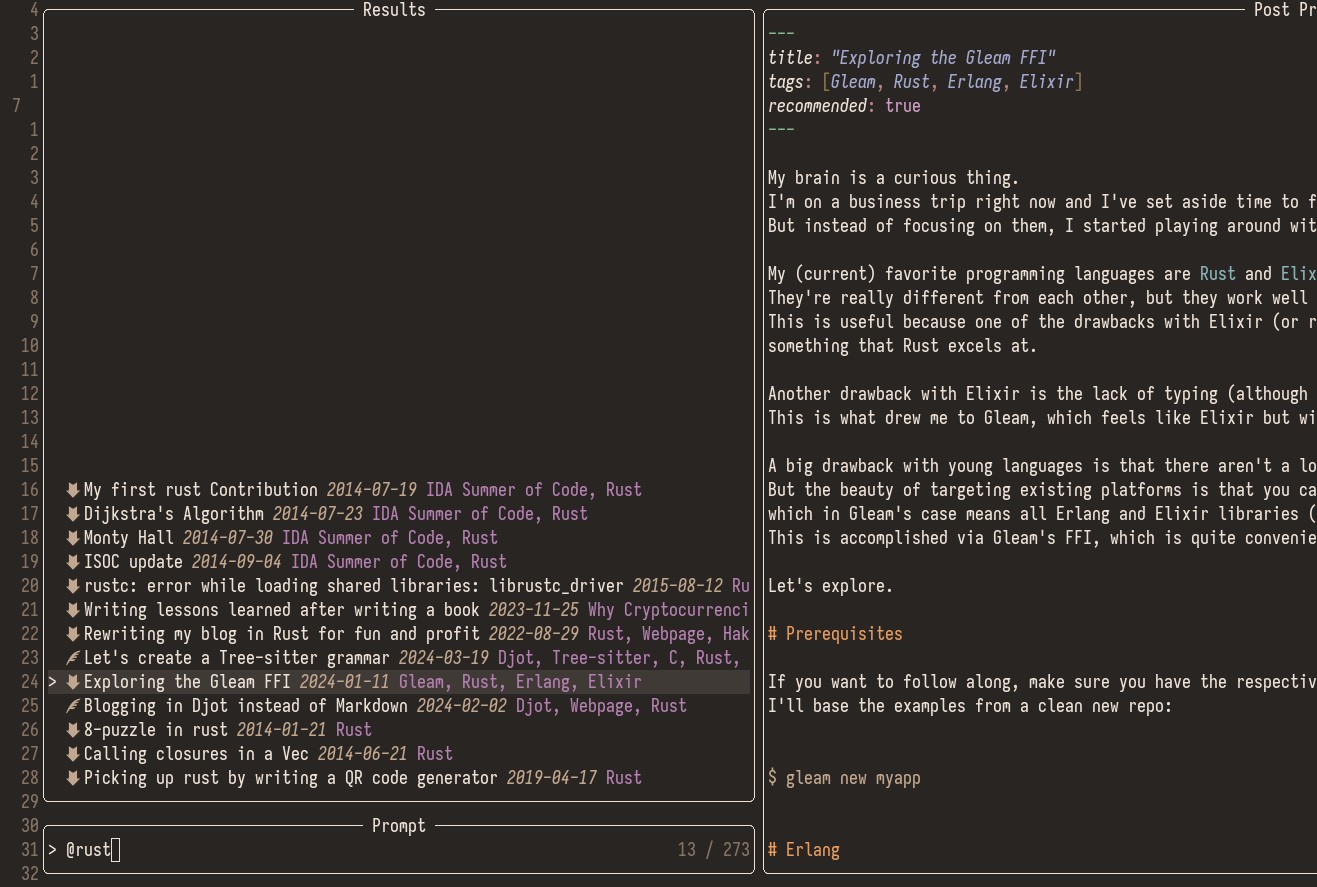
The simplest picker
It’s fairly easy to create a new picker for telescope.nvim. In it’s simplest form, all you need to do is provide a list of items:
local pickers = require("telescope.pickers")
local finders = require("telescope.finders")
pickers
.new(opts, {
finder = finders.new_table({
results = { "One", "Two", "Three" },
}),
})
:find()
Then we need to call the above code somehow, for example by wrapping it in a function and add a keymap to it:
local map = vim.keymap.set
map("n", "gd", require("blog.telescope").find_draft, { desc = "Find blog draft" })
map("n", "gp", require("blog.telescope").find_post, { desc = "Find blog post" })
Structured content
To make our simple picker handle structured content we need to:
-
Convert
resultsto a list of tables with the info we have. -
Specify an
entry_markerfunction.
A rewrite of finder in our simple picker might look like this:
finder = finders.new_table({
-- 1. Structured data inside `results`.
results = {
{ title = "One", tags = "Tag1, Tag2", path = "posts/2024-01-01-one.dj" },
{ title = "Two", tags = "Tag2", path = "posts/2024-02-02-two.dj" },
},
-- 2. A function that converts a result entry to an entry telescope understands.
entry_maker = function(entry)
return {
-- Display the post title instead of the path in the list.
display = entry.title,
-- Allow us to filter against the title and tags (typing `Tag1` finds the "One" post).
ordinal = entry.title .. entry.tags,
-- We could also save the whole entry for future usage, if we need it.
value = entry,
}
end,
}),
With this the finder displays the title of the post rather than the file path, and we can search for a post using the title and its tags.
It’s easy to add more metadata to ordinal and it’ll mostly work, but the matching is crude and it can easily misfire depending on your use-case.
Because the way fuzzy matching works, if I type lua with the hope of listing all posts tagged lua, it will also match any post that has the letters l u a in that order, which is currently almost 40 of them:
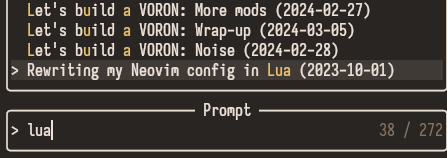
lua matches too many posts.Here I’ve also added the post date to
display.
Clearly, there’s room for improvement.
Structured filtering and sorting
Turns out that ordinal can also be a table, and you can provide your own sorter that operates on the ordinal to sort and filter.
This is the basic setup:
pickers
.new(opts, {
finder = finders.new_table({
results = {
-- `tags` is now a list.
{ title = "One", tags = { "Tag1", "Tag2" }, path = "posts/2024-01-01-one.dj" },
{ title = "Two", tags = { "Tag2" }, path = "posts/2024-02-02-two.dj" },
},
entry_maker = function(entry)
return {
display = entry.title,
-- `ordinal` is now a table containing all the entry info specified in `results`.
ordinal = entry,
}
end,
}),
-- This is the important `sorter` function.
sorter = post_sorter(opts),
})
:find()
post_sorter should return a new Sorter that describes the sorting behavior:
local
opts = opts or {}
-- We can use `fzy_sorter` for the actual fuzzy matching.
local fzy_sorter = sorters.get_fzy_sorter(opts)
return sorters.Sorter:new({
-- Allow us to filter entries as well as sorting them.
discard = true,
scoring_function = function(_, prompt, entry)
-- This mimics a standard fuzzy sorting on the entry title.
return fzy_sorter:scoring_function(prompt, entry.title)
end,
-- We could also specify a highlighter. The highlighter works fine in this case,
-- but if we modify `scoring_function` we have to modify this too.
-- I admit, I currently don't use a highlighter for my posts finder.
highlighter = fzy_sorter.highlighter,
})
end
There’s some ceremony here that I hope is clear enough.
The important thing here is the scoring_function that we’ll need to adjust.
First, the input arguments to scoring_function:
-
The first argument seems to be ignored even in Telescope’s own standard sorters, so I ignore it as well.
-
promptis the user input to the Telescope prompt as a string. -
entryis the ordinal entry thatentry_makerreturns.For instance, in our example
entrycould be this:{ title = "Two", tags = { "Tag2" }, path = "posts/2024-02-02-two.dj" }
What scoring_function should do is return a single numeric value signifying how close ordinal is to prompt, where higher means a better match.
Because we defined
discard = true if we return a value less than
0, the entry will get removed (filtered).
At first I thought this was a weird way of creating a sorting function.
I had expected a comparison function like
cmp(left, right) but after having played with it a little it seems pretty clever.
Sorter requirements
Before implementing scoring_function, let’s take a step back and figure out what behavior we want.
You could go nuts with advanced features such as boolean operators, set comparisons, and similar.
While cool, I don’t think it’s worth implementing as my requirements are fairly simple:
-
Fuzzy find on title, tags, and series.
I don’t want to require a perfect match on tags, requiring me to fully type out for example Experimental Gameplay Project would be quite annoying.
-
Explicitly filter posts by series and tags.
It’s neat if you can type some text and it filters for series or post title, but in practice I never really want that. If I want to filter against the post series, I want to be explicit about it and the same holds for tags.
-
Filter posts containing
tag1andtag2.I contemplated searching for
tag1ortag2, but what I want is to reduce the number of matches as I add more information, not increase them. -
Include published date in ordering.
At a base level I want to see newer posts before older ones. This is especially true when I first open telescope without prompting anything, then I want to see an ordered lists of all posts.
Prompt syntax
Because I want to be explicit we need some syntax to separate text we want to match against post tags, series, and title.
Simplicity is nice, and a simple solution is to prefix tags with @ and prefix series with #, separated by spaces.
I usually find that an example is worth a 1000 words, so here are some examples to shave down the precious words count:
-
@rust gleamRequire a post tag matching
rustand post title matchinggleam. -
@3d @hexRequire a post tag matching
3dand one matchinghex. -
#34Require a post series matching
34. -
build # startRequire a post with a series and post title matching
build start.
The code that converts a prompt into parts is conceptually simple: split the prompt into words and categorize them depending starting character. This is what I use:
local
local tags = {}
local series = {}
local title = {}
-- Iterates over all non-space substrings.
-- `prompt:gmatch` is syntax sugar for `string.gmatch(prompt, ..)`
for word in prompt:gmatch("([^%s]+)") do
-- Use `sub(1, 1)` to get the first character.
-- It works with empty strings too!
local fst = word:sub(1, 1)
if fst == "@" then
-- Use `sub(2)` to skip the `@`.
table.insert(tags, word:sub(2))
elseif fst == "#" then
table.insert(series, word:sub(2))
else
table.insert(title, word)
end
end
return {
tags = tags,
series = series,
-- Combine non-tagged elements into a string.
-- Could've be done outside this function but it'll always be done
-- so I thought it would be easier to join here.
title = vim.fn.join(title, " "),
}
end
I’m a bit of a Lua noob, so there may be better solutions.
Implementing scoring_function
With a plan in place, let’s go back to try to realize it. The basic idea is to match against series, tags, and title separately and add their scores at the end:
scoring_function = function(_, prompt, entry)
prompt = split_prompt(prompt)
local series_score = score_element(prompt.series, entry.series, fzy_sorter)
if series_score < 0 then
return -1
end
local tags_score = score_element(prompt.tags, entry.tags, fzy_sorter)
if tags_score < 0 then
return -1
end
local title_score = fzy_sorter:scoring_function(prompt.title, entry.title)
if title_score < 0 then
return -1
end
return series_score + tags_score + title_score
end,
Remember that a return value of
< 0 filters the entry, so we make sure to check that for each part.
This is already how fzy_sorter:scoring_function works and it will either return
< 0 for entries we should remove and a value in
0..1 otherwise.
Because the matching of tags and series is so similar, I introduced the score_element helper function:
-- Match the list `prompt_elements` against `entry_element`, either a list or a string.
local
-- We didn't prompt for this type, ignore it.
-- This is a "is list empty?" check in Lua.
if next(prompt_elements) == nil then
return 0
end
-- We prompted for this type, but entry didn't have it, so remove the entry.
-- For example if we prompt for a series, this removes all posts
-- without a series.
if not entry_element then
return -1
end
-- Convert multiple entry values to a string like `tag1:tag2`.
local entry
-- We can use `type()` to dynamically check the type of a variable
-- and act occordingly.
if type(entry_element) == "string" then
entry = entry_element
elseif type(entry_element) == "table" then
entry = vim.fn.join(entry_element, ":")
end
local total = 0
-- For each prompt element (`tag1`, `tag2`, ...), match against the entry string (`tag1:tag2`).
for _, prompt_element in ipairs(prompt_elements) do
local score = sorter:scoring_function(prompt_element, entry)
-- Require a match for every element.
if score < 0 then
return -1
end
total = total + score
end
-- Clamp score to 0..1.
-- Not strictly needed but it feels neater.
return total / #prompt_elements
end
With this in place we have a working sorter.
-
If we type regular text, then
series_scoreandtags_scorewill be0, practically ignoring them. -
A
#series_filterwill setseries_score == -1unless the post has a matching series, removing the entry. -
And typing
@tag1 @tag2will require a match for every tag, otherwisetags_score == -1that again removes the entry. - Adding the fuzzy scores together gives us a pretty good fuzzy matching behavior I feel.
The only requirement left is to order posts by date. It must be done carefully not to override the sort order we get from the fuzzy matching.
One way to do this is to sort all posts and add a post counter to each entity (so the first post would get
1 and the last
272) and then add it to the final score somehow.
This felt a little cumbersome and I wanted to see if I could implement the scoring function without having to sort the entries first.
After all, we already have the date of each post…
This is possible by placing the post on a timeline between the date of the very first post and today, and then clamping the range to
0..1.
Something like this:
-- Date of my first blog post as a number.
local beginning_of_time = 20090621
-- Today's date as a number.
local today = os.date("%Y%m%d")
-- The entry date looks like `2023-01-31`, if we remove `-` it's formatted like the above.
local entry_date = string.gsub(entry.date, "-", "")
-- Place the entry date on a 0..1 scale, where 1 is today.
-- (`1 -` reverses, otherwise 1 would be the beginning of time).
local date_score = 1 - (entry_date - beginning_of_time) / (today - beginning_of_time)
-- Date sorting is only worth 1/10 of the fuzzy scores.
-- Why? I dunno, 1 was too much and 1/10 felt good.
return series_score + tags_score + title_score + date_score / 10
Okay, I admit it’s a little hacky; but it’s a fun one that fulfills my needs.
Formatting entries

It’s possible to customize how telescope.nvim displays an entry in the results list,
see :help telescope.pickers.entry_display.
You’ll use entry_display.create() to create a formatting function that divides the display into columns, then you pass in the columns to produce the line to be displayed.
This is a basic example that divides the line into two parts; an icon and a title, together with a highlight group to colorize the parts:
local entry_display = require("telescope.pickers.entry_display")
entry_maker = function(entry)
return {
display = function(entry)
local displayer = entry_display.create({
separator = " ",
items = {
{ width = 1 },
{ remaining = true },
},
})
return displayer({
{ "", "TelescopeResultsComment" },
{ entry.value.title, "TelescopeResultsNumber" },
})
end
-- ..
}
end
The display I use to display filetype icon, title, date, tags, and series is a little more complex but the display logic is similar:
local devicons = require("nvim-web-devicons")
local telescope_utils = require("telescope.utils")
local make_display = function(entry)
-- Djot doesn't have an icon, I just picked something that looked neat.
local ext = telescope_utils.file_extension(entry.value.path)
if ext == "dj" then
ext = "tcl"
end
local icon, _ = devicons.get_icon_by_filetype(ext)
-- Tags may be a string or a table, convert it for display purposes.
local tags
if type(entry.value.tags) == "string" then
tags = entry.value.tags
elseif type(entry.value.tags) == "table" then
tags = vim.fn.join(entry.value.tags, ", ")
end
local series = entry.value.series or ""
local displayer = entry_display.create({
separator = " ",
items = {
{ width = 1 },
{ width = string.len(entry.value.title) },
{ width = string.len(entry.value.date) },
{ width = string.len(tags) },
{ remaining = true },
},
})
return displayer({
{ icon, "TelescopeResultsComment" },
-- We can skip highlight groups if we want.
entry.value.title,
{ entry.value.date, "TelescopeResultsComment" },
{ tags, "TelescopeResultsConstant" },
{ series, "TelescopeResultsOperator" },
})
end
Since I grouped the display in a function, we need to set that to display in entry_maker:
entry_maker = function(entry)
return {
display = make_display,
-- ...
}
end
I use nvim-web-devicons to map a Nerd Nerd Font icon to a filetype (also used by telescope.nvim for the standard file pickers if available).
File preview
One of the great features of telescope.nvim is the very fast preview with syntax highlighting, which we naturally must configure.
I searched through the telescope help, and found the functions new_buffer_previewer and buffer_previewer_maker that allows us to define a previewer for a file:
local previewers = require("telescope.previewers")
finder = finders.new_table({
-- ...
previewer = previewers.new_buffer_previewer({
-- Title isn't needed.
title = "Post Preview",
define_preview = function(self, entry)
-- Notice `entry.value.path` that uses our catch-all entry value.
conf.buffer_previewer_maker(entry.value.path, self.state.bufnr, {
bufname = self.state.bufname,
winid = self.state.winid,
preview = opts.preview,
-- The file encoding is needed for proper syntax highlighting.
file_encoding = opts.file_encoding,
})
end,
}),
})
I’m not sure if there’s a less verbose way to define a file previewer, as the only things I configured here are the title and the entry.value.path argument to buffer_preview_maker.
Open the selected file
We have the display of our telescope.nvim picker configured. Now how do we open the file once we’ve found it? By default there’s no way of interacting with an entry, we can only look at it.
Turns out all you need to do is add filename to entry_maker:
entry_maker = function(entry)
return {
-- Make standard action open `entry.path`.
filename = entry.path,
}
end
Finding the post data to populate the picker
So far I’ve only used placeholder data for the posts, but we need to search the file system for the markup files for the posts.
It’s not as simple as listing files in a directory, we also need to extract post metadata that’s defined in a frontmatter at the beginning of every markup file:
---toml
title = "Let's build a VORON: Noise"
tags = ["3D printing", "VORON"]
series = "voron_trident"
---
How can we do this?
With ripgrep and regex of course!

This time though I have a good reason for choosing an external tool rather than asking the backend server: I want to be able to find a post the very first thing I do when opening Neovim, and I don’t want to wait on connecting to a backend service, or requiring one running at all times.
The strategy is to use ripgrep to match the frontmatter in all posts, extract the metadata using some hacky Lua regex, and combine them into a post struct we can feed into the finder we developed.
Here’s one way that uses nvim-nio and ripgrep to find all posts under a path and extract the frontmatter:
local nio = require("nio")
local path = require("blog.path")
nio.process.run({
cmd = "rg",
args = {
"-NoHU",
"--heading",
"\\A\\---\\w*\\n(.+\\n)+^---",
-- Subpath could be `posts/` or `drafts/`, converted to an absolute path.
path.blog_path .. subpath,
},
})
Which will produce output formatted like this:
posts/2016-07-29-slackware_installation_notes.markdown
---
layout: post
title: "Slackware installation notes"
tags: Slackware
---
posts/2019-01-25-site_restyle_and_update.markdown
---
title: "Site restyle and update"
tags: ["Blog", "Web Design"]
---
posts/2024-02-27-lets_build_a_voron_more_mods.dj
---toml
title = "Let's build a VORON: More mods"
tags = ["3D printing", "VORON"]
series = "voron_trident"
---
My code for splitting the output and extracting the metadata is really gross:
local lines = vim.fn.split(output, "\n")
local posts = {}
local post = {}
for _, line in ipairs(lines) do
-- When a newline is encountered save the post and prepare for the next entry.
if line == "" then
if post.title then
table.insert(posts, post)
end
post = {}
-- Skip `---` markers.
elseif not string.match(line, "%-%-%-%w*") then
-- Try to extract all key value definitions and store them.
local key, value = string.match(line, "(%w+)%s*[:=]%s*(.+)")
if key then
-- Strip surrounding quotes.
-- Do this here because there's no non-greedy specifier that could be used
-- in the key/value regex above.
value = trim_quotes(value)
-- Split a sequence.
local seq = string.match(value, "^%[(.+)%]$")
if seq then
local parts = {}
for part in string.gmatch(seq, "%s*([^,]+)") do
table.insert(parts, trim_quotes(part))
end
value = parts
end
post[key] = value
else
-- If no key value pair is found, then we should be at the beginning with the file path.
post["path"] = line
-- Only posts have a date in the path, not drafts.
local date = string.match(line, "posts/(%d%d%d%d%-%d%d%-%d%d)%-")
if date then
post["date"] = date
else
-- Use the modified timestamp for drafts.
post["date"] = os.date("%Y-%m-%d", util.file_modified(line))
end
end
end
end
-- If output ends we might have an unsaved post.
if post.title then
table.insert(posts, post)
end
local
local stripped = string.match(s, '^"(.+)"$')
if stripped then
return stripped
else
return s
end
end
Yes, I’m using regex to parse yaml/toml values.
I could try to find a lua parser, but eeeh…
Stupid decisions aside, with all this we have a working telescope.nvim picker! I may have skipped some details, so take a look at the source code if you’re interested.